





-
 QQ空间
QQ空间
-
 QQ好友
QQ好友
-
 微信好友
微信好友
-
 新浪微博
新浪微博
正态分布
概要
正态分布是自然科学与行为科学中的定量现象的一个方便模型。各种各样的心理学测试分数和物理现象比如光子计数都被发现近似地服从正态分布。尽管这些现象的根本原因经常是未知的,理论上可以证明如果把许多小作用加起来看做一个变量,那么这个变量服从正态分布(在R.N.Bracewell的Fourier transform and its application中可以找到一种简单的证明)。正态分布出现在许多区域统计:例如,采样分布均值是近似地常态的,即使被采样的样本的原始群体分布并不服从正态分布。另外,正态分布信息熵在所有的已知均值及方差的分布中最大,这使得它作为一种均值以及方差已知的分布的自然选择。正态分布是在统计以及许多统计测试中最广泛应用的一类分布。在概率论,正态分布是几种连续以及离散分布的极限分布。
历史
正态分布最早是棣莫弗在1718年著作的书籍的( Doctrine of Change ),及1734年发表的一篇关于二项分布文章中提出的,当二项随机变数的位置参数n很大及形状参数p为1/2时,则所推导出二项分布的近似分布函数就是正态分布。拉普拉斯在1812年发表的《分析概率论》( Theorie Analytique des Probabilites )中对棣莫佛的结论作了扩展到二项分布的位置参数为n及形状参数为1>p>0时。现在这一结论通常被称为棣莫佛-拉普拉斯定理。
拉普拉斯在误差分析试验中使用了正态分布。勒让德于1805年引入最小二乘法这一重要方法 ;而 高斯则宣称他早在1794年就使用了该方法,并通过假设误差服从正态分布给出了严格的证明。
“钟形曲线”这个名字可以追溯到Jouffret他在1872年首次提出这个术语"钟形曲面",用来指代二元正态分布(bivariate normal)。正态分布这个名字还被Charles S. Peirce、Francis Galton、Wilhelm Lexis在1875分别独立地使用。这个术语是不幸的,因为它反映和鼓励了一种谬误,即很多概率分布都是常态的。(请参考下面的“实例”)
这个分布被称为“常态”或者“高斯”正好是Stigler名字由来法则的一个例子,这个法则说“没有科学发现是以它最初的发现者命名的”。
正态分布的定义
有几种不同的方法用来说明一个随机变量。最直观的方法是概率密度函数,这种方法能够表示随机变量每个取值有多大的可能性。累积分布函数是一种概率上更加清楚的方法,请看下边的例子。还有一些其他的等价方法,例如cumulant、特征函数、动差生成函数以及cumulant-生成函数。这些方法中有一些对于理论工作非常有用,但是不够直观。请参考关于概率分布的讨论。
概率密度函数
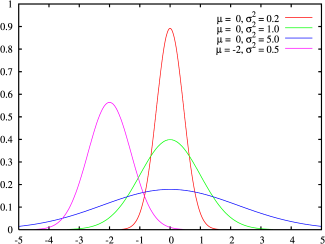
四个不同参数集的概率密度函数(绿色线代表标准正态分布)
正态分布 的概率密度函数均值为 μ μ --> {\displaystyle \mu } 方差为 σ σ --> 2 {\displaystyle \sigma ^{2标准差 (或标准差 σ σ --> {\displaystyle \sigma } )是高斯函数的一个实例:
( 请看指数函数以及 π π --> {\displaystyle \pi } . )
如果一个随机变量 X {\displaystyle X} 服从这个分布,我们写作 X {\displaystyle X} ~ N ( μ μ --> , σ σ --> 2 ) {\displaystyle N(\mu ,\sigma ^{2})} . 如果 μ μ --> = 0 {\displaystyle \mu =0} 并且 σ σ --> = 1 {\displaystyle \sigma =1} ,这个分布被称为 标准正态分布 ,这个分布能够简化为
右边是给出了不同参数的正态分布的函数图。
正态分布中一些值得注意的量:
密度函数关于平均值对称
平均值与它的众数(statistical mode)以及中位数(median)同一数值。
函数曲线下68.268949%的面积在平均数左右的一个标准差范围内。
95.449974%的面积在平均数左右两个标准差 2 σ σ --> {\displaystyle 2\sigma } 的范围内。
99.730020%的面积在平均数左右三个标准差 3 σ σ --> {\displaystyle 3\sigma } 的范围内。
99.993666%的面积在平均数左右四个标准差 4 σ σ --> {\displaystyle 4\sigma } 的范围内。
函数曲线的反曲点(inflection point)为离平均数一个标准差距离的位置。
累积分布函数
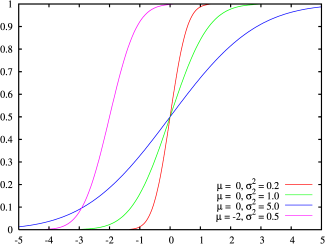
上图所示的概率密度函数的累积分布函数
累积分布函数是指随机变数 X {\displaystyle X} 小于或等于 x {\displaystyle x} 的概率,用概率密度函数表示为
正态分布的累积分布函数能够由一个叫做误差函数的特殊函数表示:
标准正态分布 的累积分布函数习惯上记为 Φ Φ --> {\displaystyle \Phi } ,它仅仅 是指 μ μ --> = 0 {\displaystyle \mu =0} , σ σ --> = 1 {\displaystyle \sigma =1} 时 的值,
将一般正态分布用误差函数表示的公式简化,可得:
它的反函数被称为反误差函数,为:
该分位数函数有时也被称为probit函数。probit函数已被证明没有初等原函数。
正态分布的分布函数 Φ Φ --> ( x ) {\displaystyle \Phi (x)} 没有解析表达式 ,它的值可数值积分值泰勒、泰勒级数或者渐进序列近似得到。
生成函数
矩母函数
动差生成函数或矩生成函数或动差产生函数被定义为 exp --> ( t X ) {\displaystyle \exp(tX)} 的期望值。
正态分布的动差产生函数如下:
可以通过在指数函数内配平方得到。
特征函数
特征函数被定义为 exp --> ( i t X ) {\displaystyle \exp(itX)} 的期望值,其中 i {\displaystyle i} 是虚数单位. 对于一个常态分布来讲,特征函数是:
把矩生成函数中的 t {\displaystyle t} 换成 i t {\displaystyle it} 就能得到特征函数。
性质
正态分布的一些性质:
如果 X ∼ ∼ --> N ( μ μ --> , σ σ --> 2 ) {\displaystyle X\sim N(\mu ,\sigma ^{2})\,} 且 a {\displaystyle a} 与 b {\displayst实数e b} 是实数,那么 a X + b ∼ ∼ --> N ( a μ μ --> + b , ( a σ σ --> ) 2 ) {\displaystyle aX+b\sim N(a\mu +b,(a\sigma )^{2})} (参见期望值和方差).
如果 X ∼ ∼ --> N ( μ μ --> X , σ σ --> X 2 ) {\displaystyle X\sim N(\mu _{X},\sigma _{X}^{2})} 与 Y ∼ ∼ --> N ( μ μ --> Y , σ σ --> Y 2 ) {\displaystyle Y\sim N(\mu _{Y},\sigma _{Y}^{2})} 是统计独立的常态随机变量,那么:
如果 X ∼ ∼ --> N ( 0 , σ σ --> X 2 ) {\displaystyle X\sim N(0,\sigma _{X}^{2})} 和 Y ∼ ∼ --> N ( 0 , σ σ --> Y 2 ) {\displaystyle Y\sim N(0,\sigma _{Y}^{2})} 是独立常态随机变量,那么:
如果 X 1 , ⋯ ⋯ --> , X n {\displaystyle X_{1},\cdots ,X_{n}} 为独立标准常态随机变量,那么 X 1 2 + ⋯ ⋯ --> + X n 2 {\displaystyle X_{1}^{2}+\cdots +X_{n}^{2}} 服从自由度为 n 的卡方分布。
标准化常态随机变量
动差或矩( moment )
一些正态分布的一阶动差如下:
标准常态的所有二阶以上的累积量为零。
生成常态随机变量
中心极限定理
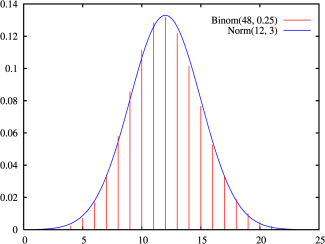
正态分布的概率密度函数,参数为μ = 12,σ = 3,趋近于 n = 48、 p = 1/4的二项分布的概率质量函数。
正态分布有一个非常重要的性质:在特定条件下,大量 统计独立的随机变量的平均值的分布趋于正态分布,这就是中心极限定理 。中心极限定理的重要意义在于,根据这一定理的结论,其他概率分布可以用正态分布作为近似。
参数为 n {\displaystyle n} 和 p {\displaystyle p} 的二项分布,在 n {\displaystyle n} 相当大而且 p {\displaystyle p} 接近0.5时近似于正态分布 (有的参考书建议仅在 n p {\displaystyle np} 与 n ( 1 − − --> p ) {\displaystyle n(1-p)} 至少为5时才能使用这一近似)。
近似正态分布平均数为 μ μ --> = n p {\displaystyle \mu =np} 且方差为 σ σ --> 2 = n p ( 1 − − --> p ) {\displaystyle \sigma ^{2}=np(1-p)} .
一泊松分布带有参数 λ λ --> {\displaystyle \lambda } 当取样样本数很大时将近似正态分布 λ λ --> {\displaystyle \lambda } .
近似正态分布平均数为 μ μ --> = λ λ --> {\displaystyle \mu =\lambda } 且方差为 σ σ --> 2 = λ λ --> {\displaystyle \sigma ^{2}=\lambda } .
这些近似值是否完全充分正确取决于使用者的使用需求
无限可分性
正态分布是无限可分的概率分布。
稳定性
正态分布是严格稳定的概率分布。
标准偏差
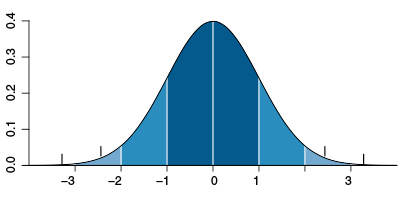
深蓝色区域是距平均值小于一个标准差之内的数值范围。在正态分布中,此范围所占比率为全部数值之 68% ,根据正态分布,两个标准差之内的比率合起来为 95% ;三个标准差之内的比率合起来为 99% 。
在实际应用上,常考虑一组数据具有近似于正态分布的概率分布。若其假设正确,则约 68.3% 数值分布在距离平均值有1个标准差之内的范围,约 95.4% 数值分布在距离平均值有2个标准差之内的范围,以及约 99.7% 数值分布在距离平均值有3个标准差之内的范围。称为“ 68-95-99.7法则 ”或“ 经验法则 ”。
常态测试
相关分布
R ∼ ∼ --> R a y l e i g h ( σ σ --> ) {\displaystyle R\sim \mathrm {Rayleigh} (\sigma )} 是瑞利分布,如果 R = X 2 + Y 2 {\displaystyle R={\sqrt {X^{2}+Y^{2}}}} ,这里 X ∼ ∼ --> N ( 0 , σ σ --> 2 ) {\displaystyle X\sim N(0,\sigma ^{2})} 和 Y ∼ ∼ --> N ( 0 , σ σ --> 2 ) {\displaystyle Y\sim N(0,\sigma ^{2})} 是两个独立正态分布。
Y ∼ ∼ --> χ χ --> ν ν --> 2 {\displaystyle Y\sim \chi _{\nu }^{2}} 是卡方分布具有 ν ν --> {\displaystyle \nu } 自由度,如果 Y = ∑ ∑ --> k = 1 ν ν --> X k 2 {\displaystyle Y=\sum _{k=1}^{\nu }X_{k}^{2}} 这里 X k ∼ ∼ --> N ( 0 , 1 ) {\displaystyle X_{k}\sim N(0,1)} 其中 k = 1 , … … --> , ν ν --> {\displaystyle k=1,\dots ,\nu } 是独立的。
Y ∼ ∼ --> C a u c h y ( μ μ --> = 0 , θ θ --> = 1 ) {\displaystyle Y\sim \mathrm {Cauchy} (\mu =0,\theta =1)} 是柯西分布,如果 Y = X 1 / X 2 {\displaystyle Y=X_{1}/X_{2}} ,其中 X 1 ∼ ∼ --> N ( 0 , 1 ) {\displaystyle X_{1}\sim N(0,1)} 并且 X 2 ∼ ∼ --> N ( 0 , 1 ) {\displaystyle X_{2}\sim N(0,1)} 是两个独立的正态分布。
Y ∼ ∼ --> Log-N ( μ μ --> , σ σ --> 2 ) {\displaystyle Y\sim {\mbox{Log-N}}(\mu ,\sigma ^{2})} 是对数正态分布如果 Y = e X {\displaystyle Y=e^{X}} 并且 X ∼ ∼ --> N ( μ μ --> , σ σ --> 2 ) {\displaystyle X\sim N(\mu ,\sigma ^{2})} .
与Lévy skew alpha-stable分布相关:如果 X ∼ ∼ --> Levy-S α α --> S ( 2 , β β --> , σ σ --> / 2 , μ μ --> ) {\displaystyle X\sim {\textrm {Levy-S}}\alpha {\textrm {S}}(2,\beta ,\sigma /{\sqrt {2}},\mu )} 因而 X ∼ ∼ --> N ( μ μ --> , σ σ --> 2 ) {\displaystyle X\sim N(\mu ,\sigma ^{2})} .
参量估计
参数的极大似然估计
概念一般化
多元正态分布的协方差矩阵的估计的推导是比较难于理解的。它需要了解谱原理(spectral theorem)以及为什么把一个标量看做一个1×1矩阵(matrix)的迹(trace)而不仅仅是一个标量更合理的原因。请参考协方差矩阵的估计(estimation of covariance matrices).
参数的矩估计
常见实例
光子计数
计量误差
饮料装填量不足与超量的概率
某饮料公司装瓶流程严谨,每罐饮料装填量符合平均600毫升,标准差3毫升的常态分配法则。随机选取一罐,求(1)容量超过605毫升的概率;(2)容量小于590毫升的概率。
容量超过605毫升的概率 = p ( X > 605)= p ( ((X-μ) /σ) > ( (605 – 600) / 3) )= p ( Z > 5/3) = p( Z > 1.67) = 1 - 0.9525 = 0.0475
容量小于590毫升的概率 = p (X < 590) = p ( ((X-μ) /σ) < ( (590 – 600) / 3) )= p ( Z < -10/3) = p( Z < -3.33) = 0.0004
6-标准差(6-sigma或6-σ)的品质管制标准
6-标准差(6-sigma或6-σ),是制造业流行的品质管制标准。在这个标准之下,一个标准常态分配的变数值出现在正负三个标准差之外,只有2* 0.0013= 0.0026 (p (Z 3) = 0.0013)。也就是说,这种品质管制标准的产品不良率只有万分之二十六。假设例中的饮料公司装瓶流程采用这个标准,而每罐饮料装填量符合平均600毫升,标准差3毫升的常态分配。那么预期装填容量的范围应该多少?
6-标准差的范围 = p ( -3 < Z < 3)= p ( - 3 < (X-μ) /σ < 3) = p ( -3 < (X- 600) / 3 < 3)= p ( -9 < X – 600 < 9) = p (591 < X < 609) 因此,预期装填容量应该介于591至609毫升之间。
生物标本的物理特性
金融变量
寿命
测试和智力分布
计算学生智商高低的概率
假设某校入学新生的智力测验平均分数与方差分别为100与12。那么随机抽取50个学生,他们智力测验平均分数大于105的概率?小于90的概率?
本例没有常态分配的假设,还好中心极限定理提供一个可行解,那就是当随机样本长度超过30,样本平均数xbar近似于一个常态变数,因此标准常态变数Z = (xbar –μ) /σ/ √n。
平均分数大于105的概率 = p(Z> (105 – 100) / (12 /√50))= p(Z> 5/1.7) = p( Z > 2.94) = 0.0016
平均分数小于90的概率 = p(Z< (90 – 100) / (12 /√50))= p(Z < -5.88) = 0.0000
计算统计应用
生成正态分布随机变量
在计算机模拟中,经常需要生成正态分布的数值。最基本的一个方法是使用标准的正态累积分布函数的反函数。除此之外还有其他更加高效的方法,Box-Muller变换就是其中之一。另一个更加快捷的方法是ziggurat算法。下面将介绍这两种方法。一个简单可行的并且容易编程的方法是:求12个在(0,1)上均匀分布的和,然后减6(12的一半)。这种方法可以用在很多应用中。这12个数的和是Irwin-Hall分布;选择一个方差12。这个随即推导的结果限制在(-6,6)之间,并且密度为12,是用11次多项式估计正态分布。
Box-Muller方法是以两组独立的随机数U和V,这两组数在(0,1]上均匀分布,用U和V生成两组独立的标准常态分布随机变量X和Y:
这个方程的提出是因为二自由度的卡方分布(见性质4)很容易由指数随机变量(方程中的lnU)生成。因而通过随机变量V可以选择一个均匀环绕圆圈的角度,用指数分布选择半径然后变换成(正态分布的)x,y坐标。
参考文献
John Aldrich.Earliest Uses of Symbols in Probability and Statistics.网上材料,2006年6月3日存在.( See "Symbols associated with the Normal Distribution". )
Abraham de Moivre (1738年). The Doctrine of Chances .
Stephen Jay Gould (1981年). The Mismeasure of Man . First edition. W. W. Norton. ISBN 978-0-393-01489-1.
R. J. Herrnstein and Charles Murray (1994年). The Bell Curve: Intelligence and Class Structure in American Life . Free Press. ISBN 978-0-02-914673-6.
Pierre-Simon Laplace (1812年). Analytical Theory of Probabilities .
Jeff Miller, John Aldrich, et al.Earliest Known Uses of Some of the Words of Mathematics. In particular, the entries for"bell-shaped and bell curve","normal" (distribution),"Gaussian", and"Error, law of error, theory of errors, etc.".网上材料,2006年6月3日存在
S. M. Stigler (1999年). Statistics on the Table , chapter 22. Harvard University Press. ( History of the term "normal distribution". )
Eric W. Weisstein et al.Normal DistributionatMathWorld.网上材料,2006年6月3日存在。
Marvin Zelen and Norman C. Severo (1964年). Probability Functions. Chapter 26 of Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables , ed, by Milton Abramowitz and Irene A. Stegun. National Bureau of Standards.
参见
中心极限定理
概率论
伽玛分布
免责声明:以上内容版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。感谢每一位辛勤著写的作者,感谢每一位的分享。

相关资料
展开



- 有价值
- 一般般
- 没价值








24小时热门







推荐阅读

关于我们

APP下载



{{item.time}} {{item.replyListShow ? '收起' : '展开'}}评论 {{curReplyId == item.id ? '取消回复' : '回复'}}